和学校对着干可以极大提升自学能力(误
这学期学校的操作系统实验课建议使用的环境是 Ubuntu 10.04 (Linux 2.6),作为一个不更新会死星人当然忍不了十年前的版本,而且尽管这是个 LTS 版本但技术支持也早就过期了。所以一不做二不休,直接上 Ubuntu 20.04 (Linux 5.4)。
然而,用最新环境的后果就是要做好完全抛弃学校提供的资料的准备。由于版本跨度太大,学校的祖传课件基本对不上了。这里记录一下摸索踩坑的全过程。
具体环境是 Windows 10 Pro 下安装 VMware Workstation 15.5.2,然后虚拟机安装 Ubuntu 20.04 x64 (初始内核版本 Linux 5.4.0-31,后续采用 Linux 5.6.14) 系统。在继续阅读前需要确保 VMware 安装完毕、虚拟机 Ubuntu 系统安装完毕和 VMware Tools 安装完毕。并且建议在继续之前先执行一次 sudo apt update && sudo apt upgrade。
请注意,本文不适用于学校资料指定的环境。同时若内核版本与上述描述版本不符,请谨慎参考本文。
专题一 & 专题二:内核编译 & 添加系统调用
由于学校实验专题二要求采用内核编译的方式增加一个系统调用,所以方便起见就两个专题一起做了。
添加系统调用
首先去 https://www.kernel.org/ 下载内核源代码,这里直接逮着最新稳定版下载,狠戳那个巨大的下载按钮。
解压出来,然后安装好依赖:
sudo apt install gcc make libncurses5-dev openssl libssl-dev build-essential pkg-config libc6-dev bison flex libelf-dev
在终端使用 uname -a 查看当前系统的内核版本,比如我这里的是:

然后我们先来增加一个自定义的系统调用。需要注意的是,在 Linux 4.15 之后,由于增加了内核页表隔离的机制,添加系统调用的方法和以前不一样了(这也就是为什么学校祖传的 2.6 版本课件在这里没用的原因)。
不过在增加系统调用之前,我们要明确几个东西:调用号、名称、参数。根据学校的实验要求,需要增加一个系统调用,它接受长整型参数,表示学号,如果学号为奇数则输出后五位,为偶数则输出后六位。
假设我想给它起名为 os_exp,这样的话它的声明应该是 long int os_exp(long long id),参数有一个,类型为 long long。注意,系统调用的返回值只能是 long类型。
接下来正式开始添加系统调用的过程。具体来说有三个需要修改的地方。
在内核源代码的 kernel 文件夹里找到 sys.c 文件。在文件末尾 #endif 之前添加下列代码。为了和原本的内核代码格式统一,建议缩进采用制表符。
SYSCALL_DEFINE1(os_exp, long long, id)
{
long int result = 0;
int end = ((id % 2 == 0) ? 6 : 5);
int i, j;
for (i = 0; i < end; i++) {
int exp = 1;
for (j = 0; j < i; j++) {
exp = exp * 10;
}
result += exp * (id % 10);
id /= 10;
}
return result;
}
要注意,这里的 for 循环不能采用内联声明(当然如果会自己改 makefile 来启用 C99 也不是不行)。不过尴尬的是我后来才想起来截取后 k 位的话直接模 10^k 就行,所以没必要用这么复杂的办法来实现。这块的函数具体实现可以忽略我写的了,没有什么参考价值了(捂脸)。
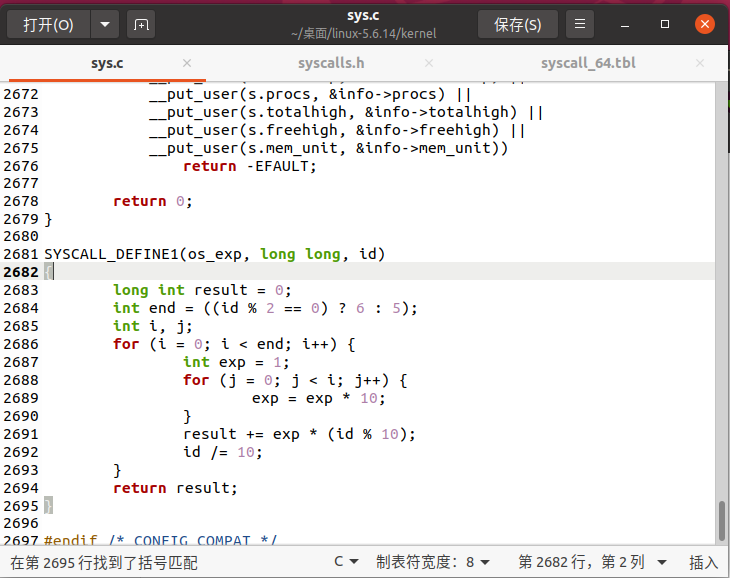
另外,和 4.15 版本之前的内核不同,这里我们需要借助 SYSCALL_DEFINEx 这个宏来添加,末尾的 x 表示参数的个数,可以是 1~6 的任意整数。这里我们只用到一个参数,所以使用 SYSCALL_DEFINE1。括号里依次是自定义系统调用的名称、参数类型、参数名称,都需要以逗号隔开,所以请务必注意 long long, id 这里是有一个逗号的。
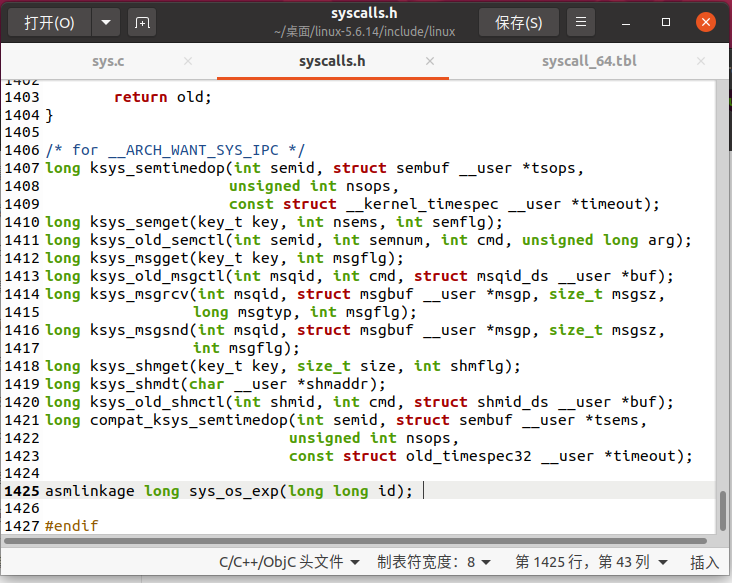
然后在 include/linux 文件夹下找到 syscalls.h 文件,也是在末尾的 #endif 之前,添加系统调用的函数声明:
asmlinkage long sys_os_exp(long long id);
这里的 asmlinkage 是告诉编译器将参数保存在栈中。
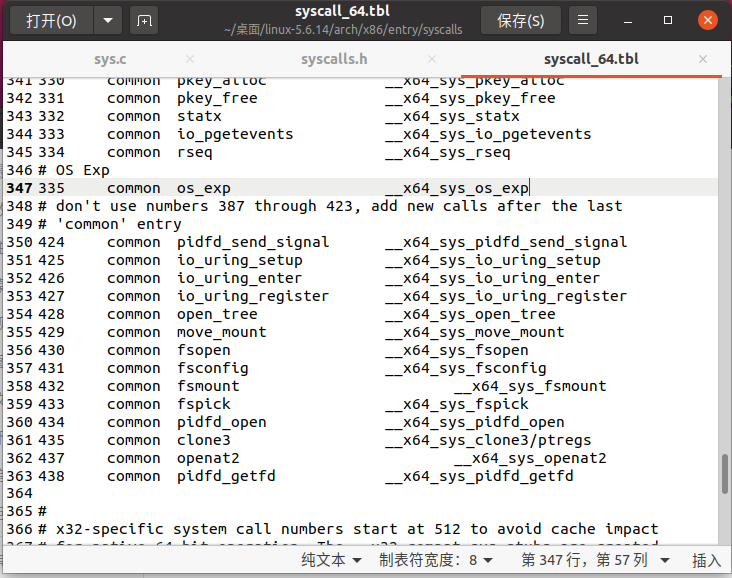
最后是在系统调用表中添加我们自定义的系统调用。在 arch/x86/entry/syscalls文件夹下找到 syscall_64.tbl 文件。在第 345 行左右,可以找到第 334 号系统调用。这个不同的内核版本可能不太一样,注意根据实际情况调整。在后面增加我们自己的 335 号系统调用:
# OS Exp 335 common os_exp __x64_sys_os_exp
# OS Exp是注释,可以不写。这里的格式是,<系统调用编号> common <系统调用名称> <系统调用的函数名称>,这四列之间请使用制表符分隔。注意系统调用的函数名称是有格式要求的,格式为 __x64_sys_<函数名>,而这里的函数名就是之前我们自己拟定的 os_exp。
确认以上三个文件修改无误之后,保存。再确认前面提到的依赖安装无误之后,下面我们进入内核编译过程。由于编译需要足够的性能和磁盘空间,保证宿主机正常工作的情况下,尽量给虚拟机分配多一点的处理器内核,另外虚拟机的磁盘空间务必不要低于 50 GB。如果之前已经编译过一次内核,现在要进行第二次编译,则需要更多空间。
编译安装内核
前期配置
终端里进入内核文件夹,比如我这里就敲 cd ~/桌面/linux-5.6.14。然后输入 sudo make menuconfig 进行一些简要的配置。这里我们主要是在版本信息中添加实验要求的学号和姓名。
用方向键选择 General Setup 然后回车,再用方向键选择第二项 Local version,在这里添加的信息将会被追加到本身的版本号 5.6.14 之后。例如我在这里填写 haha,那么最终的版本号将是 5.6.14haha,为了美观可以填写 -haha,这样最终的版本号就是 5.6.14-haha。理论上合法的字符可以是半角数字、半角字母、半角冒号、半角短横线和半角加号,保险起见我们只使用字母、数字和短横线。
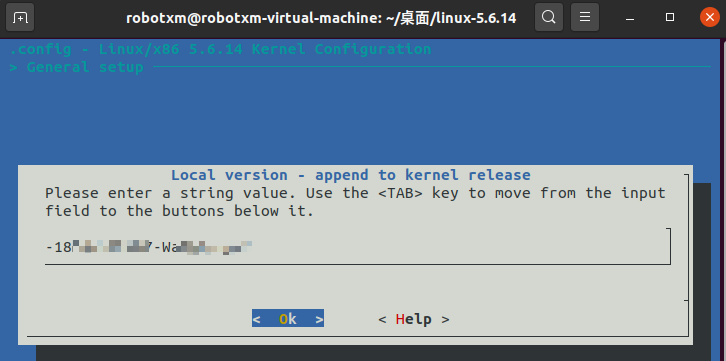
添加完成,回车。然后用 Tab 键选择 Exit 逐级退出菜单,最后会问是否要保存,当然是 Yes 回车了。
编译
接下来开始激动人心的正式编译过程。为了提升编译速度,我们采用多线程,线程数取决于为虚拟机分配的。可以在 VMware 或者 Ubuntu 设置的关于里查看。
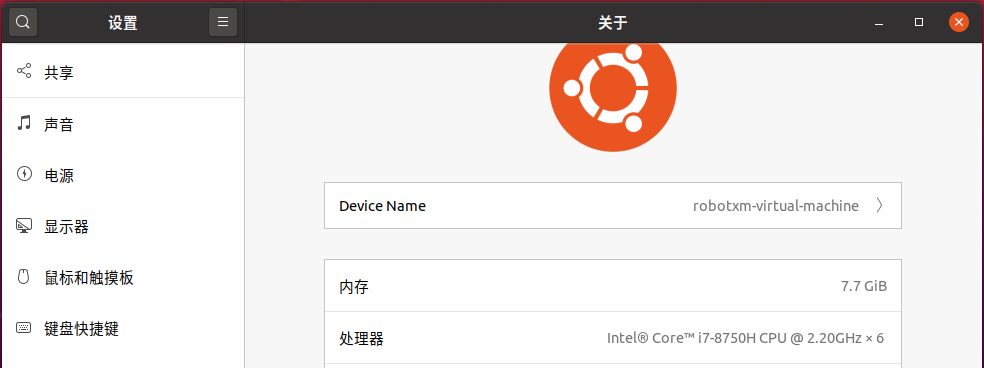
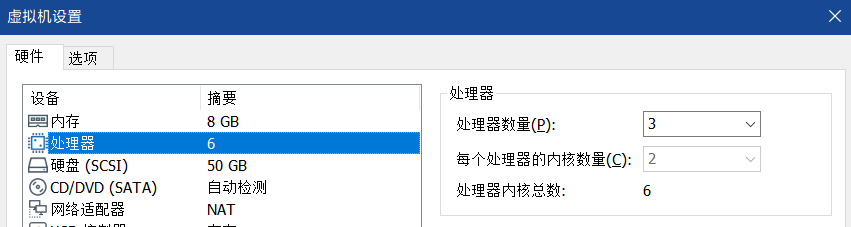
比如我给虚拟机分配了 3 个虚拟 CPU 内核,每个内核 2 个线程,那么最终可用的就是 6 个线程。在 Ubuntu 的关于里显示的就是 × 6。我需要执行的命令就是 sudo make -j6。最后的 6 根据实际情况改变。
回车之后就是漫长的等待,根据电脑性能,编译时间在 40 分钟到 3 个小时不等。编译过程中会产生大量的临时文件,一定要提前留出磁盘空间。
当看到如下图所示的提示时,说明第一阶段的编译已经基本快结束了。
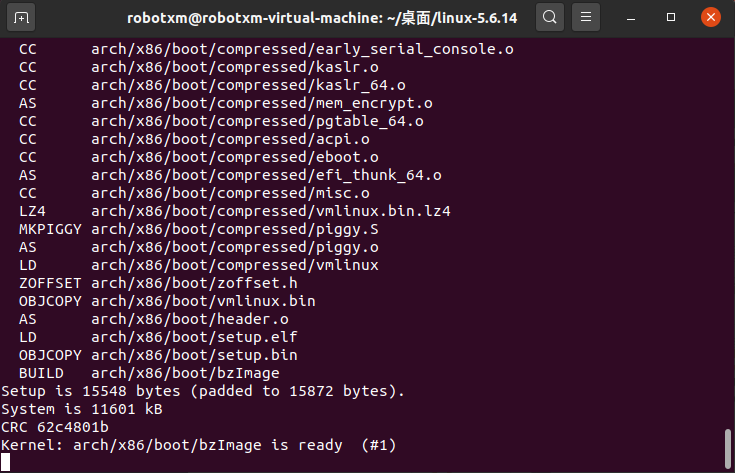
再等一会儿,待最后一点工作完成,会出现下面的提示。此时第一阶段的编译彻底完成了。
安装
继续执行 sudo make modules_install 安装内核模块。出现下图代表安装完成。
完成之后再执行 sudo make install 安装内核。
这样就算安装完成了,sudo reboot 重启静候翻车(误)。成功重启之后执行 uname -a 就可以看到我们新的内核了。

测试系统调用
接下来我们测试一下系统调用是否添加成功。编写测试代码:
#include <iostream>
#include <unistd.h>
using namespace std;
int main()
{
cout << syscall(335, 1234567890) << endl;
cout << syscall(335, 1234567891) << endl;
return 0;
}
编译运行,结果如下:
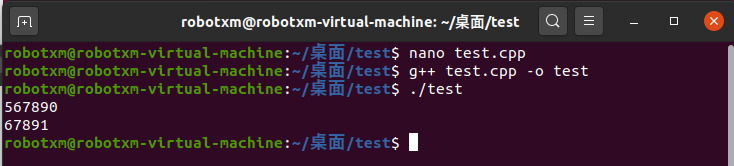
对于给定的 1234567890,输出了后六位,而对于给定的 1234567891 输出了后五位,符合预期结果。
不过因为大部分人的学号中间有连续的多个 0,截取出来的后六位或后五位实际上是不带前导零的,因此可以采用 printf("%06ld", ret) 的方法进行输出。
至此,增加系统调用以及内核编译就全部完成了。
专题三:内核模块
这个专题要求编写、编译并测试内核模块,如果可能的话通过内核模块的方式增加专题二中的系统调用。
由于这个地方关于踩坑的资料相对不是那么容易查到,所以这里我分两部分讲,第一部分只讲怎么做,第二部分再讲为什么。
How?
通过内核模块增加系统调用的思路是,修改已经映射到内存中的系统调用表,将空闲的项指向新添加的系统调用。不过由于修改这部分内存需要关闭写保护,所以我们需要先修改 cr0 寄存器的值来完成,同时需要在完成系统调用的增加之后恢复写保护。
之前我们的系统调用叫 os_exp,这次就叫 os_exp2 吧。如果之前没有再有什么改动的话,那么这次的系统调用号就确定为 336。
然后我们需要获取系统调用表 sys_call_table 的虚地址,使用以下命令:
sudo cat /proc/kallsyms | grep sys_call_table

可以看到 ffffffff98c013a0 就是当前系统调用表的虚地址。但是这个地址重启之后就会改变,所以我们不采用硬编码的办法,而是在代码中另外获取。
接下来编写内核模块代码:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/unistd.h>
#include <linux/time.h>
#include <linux/uaccess.h>
#include <linux/sched.h>
#include <linux/kallsyms.h>
#define __NR_syscall 336 // 系统调用号
unsigned int clear_and_return_cr0(void);
void setback_cr0(unsigned int val);
int orig_cr0; // 保存 CR0 寄存器原始值
unsigned long *sys_call_table = 0;
static int (*anything_saved)(void); // 定义函数指针用于保存系统调用
typedef asmlinkage long (*sys_call_ptr_t)(const struct pt_regs *);
/**
* 设置 CR0 的第 16 位为 0
*/
unsigned int clear_and_return_cr0(void)
{
unsigned int cr0 = 0;
unsigned int ret;
// 64 位系统,借助 RAX 寄存器
asm volatile("movq %%cr0, %%rax"
: "=a"(cr0)); // 将 CR0 的值移动到 RAX 并输出到变量 cr0 中
ret = cr0;
cr0 &= 0xfffeffff; // 将变量 cr0 值的第 16 位置零,并将修改后的值写入 CR0 寄存器
asm volatile("movq %%rax, %%cr0" ::"a"(cr0)); // 将 CR0 中的值读到 RAX 中,再将 RAX 的值放到 EAX 中
return ret;
}
/**
* 将变量 val 的值存放在 RAX 中,再将 RAX 的值放在 CR0 中
*/
void setback_cr0(unsigned int val)
{
asm volatile("movq %%rax, %%cr0" ::"a"(val));
}
/**
* 自定义的系统调用
*/
static asmlinkage long sys_os_exp2(const struct pt_regs *regs)
{
long result;
long long id;
id = (long long)regs->di;
result = id % (id % 2 == 0 ? 1000000 : 100000);
printk("result = %ld", result);
return result;
}
/**
* 内核模块的入口函数
*/
static int __init init_addsyscall(void)
{
printk("Initializing os_exp2...\n");
sys_call_table = (unsigned long *)kallsyms_lookup_name("sys_call_table"); // 获取系统调用服务首地址
printk("sys_call_table: 0x%p\n", sys_call_table);
anything_saved = (int (*)(void))(sys_call_table[__NR_syscall]); // 保存原始系统调用
orig_cr0 = clear_and_return_cr0(); // 设置 CR0 可更改
sys_call_table[__NR_syscall] = (unsigned long)&sys_os_exp2; // 更改原始的系统调用服务地址
setback_cr0(orig_cr0); // 设置为原始的只读 CR0
return 0;
}
/**
* 卸载内核模块
*/
static void __exit exit_addsyscall(void)
{
orig_cr0 = clear_and_return_cr0(); // 设置 CR0 中对 sys_call_table 的更改权限
sys_call_table[__NR_syscall] = (unsigned long)anything_saved; // 设置 CR0 可更改
setback_cr0(orig_cr0); // 恢复原有的中断向量表中的函数指针的值
printk("Exiting os_exp2...\n"); // 恢复原有的 CR0 的值
}
module_init(init_addsyscall);
module_exit(exit_addsyscall);
MODULE_LICENSE("GPL");
然后是 Makefile 文件(注意大小写)。注意 obj-m 字段,如果上面的内核模块源代码保存文件名是 syscall.c,那么这里就是 syscall.o,需要对应。
obj-m:=syscall.o PWD:= $(shell pwd) KERNELDIR:= /lib/modules/$(shell uname -r)/build EXTRA_CFLAGS= -O0 all: make -C $(KERNELDIR) M=$(PWD) modules clean: make -C $(KERNELDIR) M=$(PWD) clean
保存之后,sudo make 编译。
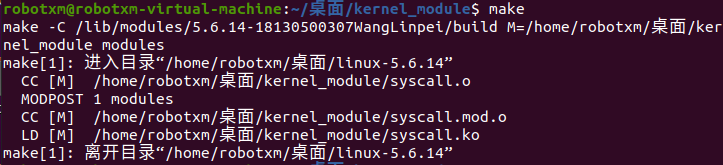
结束后会在当前目录下生成一个 syscall.ko 文件,我们继续使用 sudo insmod syscall.ko 来安装内核模块。完成之后,编写测试代码。
#include <stdio.h>
#include <unistd.h>
int main()
{
long long id;
scanf("%lld", &id);
printf(id % 2 == 0 ? "%06ld\n" : "%05ld\n", syscall(336, id));
return 0;
}
输出结果如下:
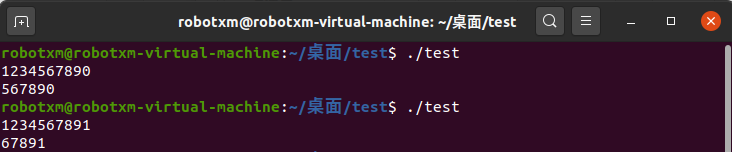
可以看到符合预期。另外,由于我这里写了一句 printk("result = %ld", result),所以在内核输出里也能看到如下内容:

Why?
上面的代码参考了《Linux 系统调用(二)——使用内核模块添加系统调用(无需编译内核)》这篇文章。但是这类文章有一个普遍的问题就是,演示中很少或者根本不会涉及需要传参的系统调用,所以就会隐藏很多坑。
就这篇文章来说,要注意的是,从 4.14 版本开始,由于破坏性改动,头文件中需要引入的是 linux/uaccess.h,而不是网上其他资料里写的 asm/uaccess.h。具体在内核中的变动可以看这里。所以对于上面提到的那篇文章中,我就比较好奇,为什么看起来作者使用的是 5.3 版本内核但是没有问题。
然后是一直造坑的含参系统调用的编写。如果直接简单粗暴地像编写普通函数那样的话,在后面调用自定义系统调用时,并不能正确地返回结果——实际上如果有输出调试的话,会发现根本不会触发我们增加的系统调用。
问题的罪魁祸首再次指向参数传递。根据 Stack Overflow 上的这篇提问中的回答,从 4.17 版本开始,64 位(x86-64)的内核会采用包装的方式来调用系统调用实际的函数,这也就导致了不能直接传参——这里连 SYSCALL_DEFINEx 都救不了。
然而总是有办法的,从回答中我们知道,唯一的办法是传入一个结构体指针 pt_regs,这个结构体里保存了传入的参数(实际上这个结构里的对应的是寄存器中的值,这些寄存器用于保存调用函数时传入参数)。
那寄存器和参数的对应关系又是什么呢?根据回答中提到的这个链接中的内容,如果传入的参数个数小于等于 4 ,那么 pt_regs 中 di、si、dx、r10 这 4 个寄存器分别对应了第 1 ~ 4 个参数。
这样的话问题就迎刃而解了,我们的 sys_os_exp2 函数只需要一个参数,那么就使用di这个寄存器即可。
具体的使用方法是,在开头我们需要 typedef asmlinkage long (*sys_call_ptr_t)(const struct pt_regs *) 来声明 pt_regs ——是的,实际上这只是个别名而已。然后,修改我们的函数头部为 static asmlinkage long sys_os_exp2(const struct pt_regs *regs)。注意这里的参数,是且只能是这个。在实现中使用 (long long)regs->di 来获取实际传入的参数值。这里的强制类型转换是因为我们期待的入参是 long long 类型。这样修改之后,就可以正常使用我们通过内核模块添加的系统调用了。
More
上面只提到了在传入 4 个参数时,参数和寄存器的对应关系。但前面在专题一里提到,系统调用可以拥有最多 6 个参数,那么第 5 个和第 6 个参数对应又保存在寄存器的哪里呢?
从 Linux 内核关于针对 x86_64 架构引入 pt_regs 结构体这个补丁的更改记录中,我们可以看到下面的代码:
regs->ax = sys_call_table[nr]( regs->di, regs->si, regs->dx, regs->r10, regs->r8, regs->r9);
这表明,6 个参数对应的寄存器分别是 di、si、dx、r10、r8 和 r9。至于 ax 寄存器,则用于在执行系统调用之前存储系统调用号,以及在执行完成之后存储返回值。不过,尽管这里 di、si、dx 和 ax 看起来像是 16 位的通用寄存器,实际上在内核中会自动使用 64 位对应的 rdi、rsi、rdx 和 rax 寄存器。另外三个则是 64 位处理器相对 32 位处理器新增的寄存器。
说到这里又不得不稍微扯一点计算机组成原理的知识了。我们看一下 x86-64 的通用寄存器(下图)。这里就有疑问了,从表里来看,六个参数明明对应的是 rdi、rsi、rdx、rcx、r8 和 r9,为什么在上面,第 4 个参数使用的却是 r10 寄存器呢?

这个问题在 Stack Overflow 上也是有解答的。这里我稍微扯得开一点。首先我们需要看一下 x86-64 的 ABI,在第 148 页(对应文档实际第 149 页)里面有这么一段描述:
1. User-level applications use as integer registers for passing the sequence
%rdi,%rsi,%rdx,%rcx,%r8and%r9. The kernel interface uses%rdi,%rsi,%rdx,%r10,%r8and%r9.2. A system-call is done via the syscall instruction. The kernel destroys registers
System V Application Binary Interface AMD64 Architecture Processor Supplement (With LP64 and ILP32 Programming Models) Version 1.0%rcxand%r11.
在 x86-64 架构中,系统调用是通过 syscall 指令完成的,rcx 和 r11 这两个寄存器的内容会在指令中被破坏。所以采用 r10 来代替 rcx。那么新的问题又来了,为什么 rcx 和 r11 的内容会被破坏呢?
我们需要继续看 ABI,不过这次我们要去看 Intel 的指令集手册,在第 4-668 页(对应实际文档第 1320 页)关于 SYSCALL 指令,有这么一段描述:
SYSCALL invokes an OS system-call handler at privilege level 0. It does so by loading RIP from the IA32_LSTAR MSR (after saving the address of the instruction following SYSCALL into RCX). (The WRMSR instruction ensures that the IA32_LSTAR MSR always contain a canonical address.)
SYSCALL also saves RFLAGS into R11 and then masks RFLAGS using the IA32_FMASK MSR (MSR address C0000084H); specifically, the processor clears in RFLAGS every bit corresponding to a bit that is set in the IA32 FMASK MSR.
Intel 64 and IA-32 Architectures Software Developer's Manual, Volume 2 (2A, 2B, 2C & 2D) Instruction Set Reference, A-Z
简单来说就是,rcx 寄存器会被用来保存返回的地址,但是在这之后又会立刻从 IA32_LSTAR 这个 MSR(Model-Specified Register,中文意译为“仅限特定型号 CPU 的寄存器”)中加载 rip(也就是我们熟知的指令指针寄存器,不过是 64 位架构中对应的寄存器)。此时 rcx 原有的内容就被清除了。而r11寄存器内容被清除是因为 SYSCALL 指令会把 RFLAGS 保存到 r11 中,然后使用 IA32_FMASK 这个 MSR 来标记 RFLAGS。
基于上述原因,rcx 和 r11 在系统调用过程中无法用来传递参数,于是 rcx 就被 r10 代替了。当然这里又有一个问题了,为什么只能用 r10 而不能用后面的 r12~r15 中的任意一个呢?
这里我们就需要考虑通用寄存器的分类了。上面的通用寄存器表里指出,通用寄存器分为调用者保存(Caller-saved)和被调者保存(Callee-saved)两类。在 16 个通用寄存器中,rbp、rbx、r12、r13、r14 和 r15 属于被调者保存,剩下的 rax、rcx、rdx、rdi、rsi、rsp、r8、r9、r10 和 r11 属于调用者保存。用于保存函数入参的寄存器需要是属于调用者保存这一类的,因此在排除掉 r11 之后,剩下的可供使用的只有 r10 这一个寄存器了。这也解释了为什么系统调用最多只能有 6 个参数,因为寄存器不够用了啊 23333。
还有一个问题,为什么函数入参需要放在调用者保存的寄存器里呢?实际上,“调用者保存”和“被调用者保存”的含义指的是,谁需要使用,谁就去“负责”保存。基于此,我个人的理解是,由于被调函数不需要关心调用者是否还需要使用寄存器里的值,所以可能会“随意”修改,这时候如果调用者需要再次使用传入的值的话,就需要自己提前保存到栈或者其他地方并在需要使用的时候自行恢复。不过因为我确实没有找到有对这里做出详细解释的资料,这个理解可能不是特别准确。
专题四:设备驱动
在这个专题中,我们需要完成的是编写一个设备驱动满足作业要求。这应该是四个专题里最不需要折腾的一个了。
设备驱动的本质还是内核模块,只不过不涉及系统调用,不需要使用奇怪的传参方式。
假定我们这次的设备驱动名为 rwbuf,编写 rwbuf.c 源代码:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/uaccess.h>
// 用于 ioctl 命令
#define RW_CLEAR 0x909090
// 设备名称
#define DEVICE_NAME "rwbuf"
// 缓冲区最大长度
#define RWBUF_MAX_SIZE 1024
// 当前缓冲区长度,注意设置为 12 是因为要求在内核模块安装完成之后需要立刻能读出学号
static int rwlen = 12;
// 缓冲区,初始值需要是学号以便能在设备安装后立刻读出
static char rwbuf[RWBUF_MAX_SIZE] = "12345678901";
// 锁机制,保证只能有一个打开的设备。0 为未打开,1 为已打开
static int inuse = 0;
/**
* 打开设备
*
* @return 0 表示成功,-1 表示失败
*/
int rwbuf_open(struct inode *inode, struct file *file)
{
if (inuse == 0)
{
inuse = 1;
// increase the use count in struct module
try_module_get(THIS_MODULE);
return 0;
}
else
return -1;
}
/**
* 关闭设备
*
* @return 0 表示成功
*/
int rwbuf_release(struct inode *inode, struct file *file)
{
inuse = 0;
// decrease the use count in struct module
module_put(THIS_MODULE);
return 0;
}
/**
* 从设备中读取内容
*
* @param buf 存放读取内容的缓冲区
* @return 正数表示成功,-1 表示错误
*/
ssize_t rwbuf_read(struct file *file, char *buf, size_t count, loff_t *f_pos)
{
if (rwlen > 0 && rwlen <= RWBUF_MAX_SIZE)
{
copy_to_user(buf, rwbuf, count);
printk("[rwbuf] Read successful. After reading, rwlen = %d\n", rwlen);
return count;
}
else
{
printk("[rwbuf] Read failed. rwlen = %d\n", rwlen);
return -1;
}
}
/**
* 将内容写入到设备
*
* @param buf 存放待写入内容的缓冲区
* @return 正数表示成功,-1 表示错误
*/
ssize_t rwbuf_write(struct file *file, const char *buf, size_t count, loff_t *f_pos)
{
if (count > 0)
{
copy_from_user(rwbuf, buf, count > RWBUF_MAX_SIZE ? RWBUF_MAX_SIZE : count);
rwlen = count > RWBUF_MAX_SIZE ? RWBUF_MAX_SIZE : count;
printk("[rwbuf] Write successful. After writing, rwlen = %d\n", rwlen);
return count;
}
else
{
printk("[rwbuf] Write failed. Length of string to be written = %lu\n", count);
return -1;
}
}
/**
* ioctl 操作
*
* @param arg 要执行的操作
* @return 0 表示成功,-1 表示错误
*/
long rwbuf_ioctl(struct file *file, unsigned int cmd, unsigned long arg)
{
printk("[rwbuf] [RW_CLEAR:%x],[cmd:%x]\n", RW_CLEAR, cmd);
if (cmd == RW_CLEAR) // 清空缓冲区
{
rwlen = 0;
printk("[rwbuf] Do ioctl successful. After doing ioctl, rwlen = %d\n", rwlen);
return 0;
}
else // 无效命令
{
printk("[rwbuf] Do ioctl failed. rwlen = %d\n", rwlen);
return -1;
}
}
static struct file_operations rwbuf_fops =
{
open : rwbuf_open,
release : rwbuf_release,
read : rwbuf_read,
write : rwbuf_write,
unlocked_ioctl : rwbuf_ioctl
};
static int __init rwbuf_init(void)
{
int ret = -1;
printk("[rwbuf] Initializing device...\n");
// 60: 主设备号,与创建 /dev/rwbuf 时使用的对应
// DEVICE_NAME: 上面定义的设备名称
// &rwbuf_fops: VFS 相关
ret = register_chrdev(60, DEVICE_NAME, &rwbuf_fops);
if (ret != -1)
printk("[rwbuf] Initialize successful\n");
else
printk("[rwbuf] Initialize failed\n");
return ret;
}
static void __exit rwbuf_exit(void)
{
unregister_chrdev(60, DEVICE_NAME);
printk("[rwbuf] Uninstall successful\n");
}
module_init(rwbuf_init);
module_exit(rwbuf_exit);
MODULE_LICENSE("GPL");
因为作业要求在安装之后立刻能读出学号,所以我们需要提前保存。
然后同样是 Makefile 文件,注意大小写和字段匹配:
obj-m := rwbuf.o KERNELDIR := /lib/modules/$(shell uname -r)/build PWD := $(shell pwd) modules: $(MAKE) -C $(KERNELDIR) M=$(PWD) modules clean: rm -rf *.o *~ core .depend .*.cmd *.ko *.mod.c .tmp_versions modules.order Module.symvers
编写完成之后,依旧执行 sudo make 编译,然后会得到 rwbuf.ko 文件。
为了便于下一步观察输出,这里我们先使用 sudo dmesg -c 清空已有的内核输出。
然后,在安装内核模块之前,我们需要创建设备文件,输入以下命令:
sudo mknod /dev/rwbuf c 60 0
c 表示这是一个字符型设备,60 表示设备的主设备号,0 表示设备的次设备号。
为了避免权限问题,使用 sudo chmod 777 /dev/rwbuf 修改设备文件的权限。注意,这里只为实验目的才这么操作,在其他情况下除非必要,否则请绝对不要随意将文件权限设置为 777。
接下来使用 sudo insmod rwbuf.ko 安装设备驱动。完成之后编写下列测试代码:
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/ioctl.h>
#define DEVICE_NAME "/dev/rwbuf"
#define RW_CLEAR 0x909090
int main()
{
int fd;
int ret;
char buff[1024];
printf("Open device %s...\n", DEVICE_NAME);
fd = open(DEVICE_NAME, O_RDWR);
if (fd == -1)
{
printf("Open device error\n");
return 0;
}
printf("\nRead student id...");
if (read(fd, buff, 12) > 0)
{
buff[11] = '\0';
printf("%s\n", buff);
}
else
{
printf("Failed\n");
return 0;
}
printf("Write 1100 'a'...");
if (write(fd, "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa", 1100) == -1)
{
printf("Failed\n");
return 0;
}
printf("\nRead from device...");
if (read(fd, buff, 1024) > 0)
{
buff[1023] = '\0';
printf("%s\n", buff);
}
else
{
printf("Failed\n");
return 0;
}
printf("\nClear device...");
if (ioctl(fd, RW_CLEAR) == 0)
printf("Successful\n");
else
{
printf("Failed\n");
return 0;
}
ret = close(fd);
printf("Device closed\n");
return 0;
}
编译运行,如果一切无误的话,会看到下列输出:
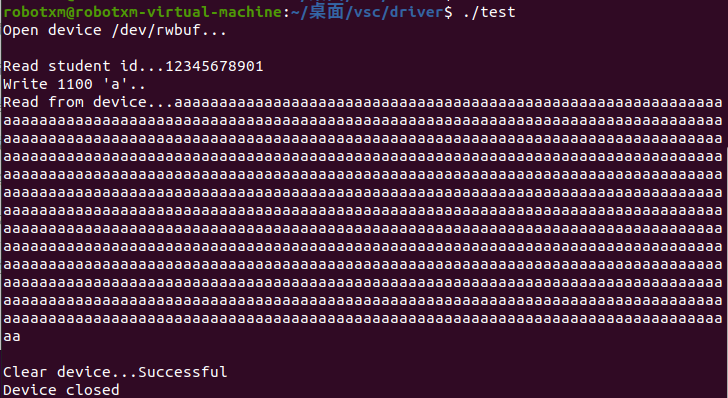
然后使用 sudo rmmod rwbuf.ko 卸载驱动。完成之后执行 dmesg,会看到以下内核输出:
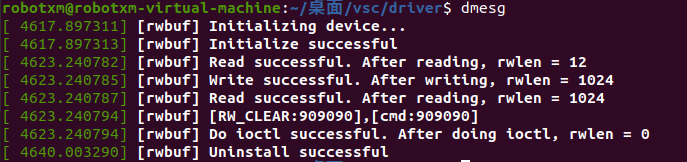
这样我们的设备驱动就编写并测试完成了。
最后
至此,操作系统课程设计实验的四个专题就全部完成了。在跌跌撞撞的踩坑中其实还是学到不少东西的。
感谢学长造福西电软工学子
哈哈,现在我们第三专题让读进程信息,简单多了(bushi)
大佬好!我参考大佬的文章写了一个kernel module,但是在rmmod的时候回报错:
[292887.945127] BUG: unable to handle page fault for address: ffffffffc103a06e
[292887.945127] #PF: supervisor instruction fetch in kernel mode
[292887.945128] #PF: error_code(0x0010) - not-present page
请问这个应该怎么解决呢?
更详细的内容我记录在了我的博客上面https://ya0guang.com/notes/KernelModule/
还望大佬能够不吝赐教! :redface:
贵校的操作系统实验不知道比我们高到哪里去了(
当时一看到“ls和vi的使用”我就一瞬跑路(
那当然 ls 和 vi 什么的也是有的,不过是算在预备专题里的x