得把产品哄好咯。
前段时间组里同事做的需求里,有一项是需要实现限制 EditText 的输入长度,计算规则为:总上限 30 个字,汉字和 Emoji 算一个字,英文和数字算 0.5 个字。这个事情就不是简单的用 android:maxLength XML 属性就能完成的了,趁此机会刚好可以了解下几种不同的限制方式的区别。
android:maxLength 属性
这个属性是 Android 开发中最常用的了,只需要简单地在 XML 里声明就可以轻松实现限制:
<EditText
android:id="@+id/et_test"
android:layout_width="200dp"
android:layout_height="wrap_content"
android:maxLength="30"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintTop_toBottomOf="@id/image_view" />
这个属性本质上是给 EditText 添加了一个 InputFilter 的实现 LengthFilter。由于 EditText 继承自 TextView,在 AOSP 源码里我们可以看到:
public class TextView extends View implements ViewTreeObserver.OnPreDrawListener {
// ...
public TextView(
Context context, @Nullable AttributeSet attrs, int defStyleAttr, int defStyleRes) {
super(context, attrs, defStyleAttr, defStyleRes);
// ...
int maxlength = -1;
// ...
for (int i = 0; i < n; i++) {
int attr = a.getIndex(i);
switch (attr) {
// ...
case com.android.internal.R.styleable.TextView_maxLength:
maxlength = a.getInt(attr, -1);
break;
// ...
}
}
// For addressing b/145128646
// For the performance reason, we limit characters for single line text field.
if (bufferType == BufferType.EDITABLE && singleLine && maxlength == -1) {
mSingleLineLengthFilter = new InputFilter.LengthFilter(
MAX_LENGTH_FOR_SINGLE_LINE_EDIT_TEXT);
}
if (mSingleLineLengthFilter != null) {
setFilters(new InputFilter[] { mSingleLineLengthFilter });
} else if (maxlength >= 0) {
setFilters(new InputFilter[] { new InputFilter.LengthFilter(maxlength) }); // <-
} else {
setFilters(NO_FILTERS);
}
}
有关于 InputFilter 会在后面讲到,这里只需要知道 maxLength 的底层实现是依赖于前者就好。
不过,使用 maxLength 的时候,对于一般的英文、数字、汉字字符是比较好使的,但对于 Emoji 来说,会出现一些奇怪的问题。比如这个例子,我们明明只输入了 2 个汉字、3 个英文字母、3 个数字和 1 个 Emoji,但统计出来居然有 19 个字。

然后是这个例子,预期输入的三个一样的 Emoji,可是最后却变成了另外三个,并且这几个就占用了 30 个字符。

要想知道这个原因,还是来看 InputFilter.LengthFilter 的源码:
public static class LengthFilter implements InputFilter {
@UnsupportedAppUsage
private final int mMax;
// ...
public CharSequence filter(CharSequence source, int start, int end, Spanned dest,
int dstart, int dend) {
int keep = mMax - (dest.length() - (dend - dstart));
// ...
}
// ...
}
这里省略了一些对这一节要讲的内容不重要的东西,只要看到这里有一个 dest.length(),就能立刻意识到问题所在了。
熟悉 Java 的应该知道对于字符串来说,length() 和 codePointCount() 返回的值在某些情况下是不一样的。在 Java 8 中字符串的内部实现是 char[],采用 UTF-16 编码;而从 Java 9 开始变成了 byte[],采用 Latin-1 或者 UTF-16 编码。
Latin-1 属于单字节编码,规则比较简单,同时向下兼容 ASCII。Unicode 范围是 0x00 ~ 0xFF,在 0x00 ~ 0x7F 之间和 ASCII 一致,0x80 ~ 0x9F 之间是控制字符,0xA0 ~ 0xFF 之间是文字符号。
UTF-16 则是双字节编码,Unicode 范围是 0x000000 ~ 0x10FFFF。编码规则为:
| Unicode 范围 | UTF-16 编码方式 |
|---|---|
| 基本平面 U+0000 ~ 0+FFFF | 2 字节存储,编码后等于原始 Unicode |
| 扩展平面 U+10000 ~ U+10FFFF | 先将原始 Unicode 减去 0x10000,并补 0 得到一个二进制 20 位长的值。 然后将这 20 位分为高 10 位和低 10 位。 对高 10 位加上 0xD800(1101 1000 0000 0000),得到 2 字节长的高位代理(High Surrogate,也称前导代理 Leading Surrogate)。 对于低 10 位加上 0xDC00(1101 1100 0000 0000),得到 2 字节长的低位代理(Low Surrogate,也称后尾代理 Trailing Surrogate)。 这 4 个字节组成了 UTF-16 在扩展平面的编码。 |
在 Java 9 之前的版本,字符串全部为 UTF-16 编码,在 Java 9 和之后的版本,如果字符串中出现了 Latin-1 无法编码的字符,则整个字符串全部使用 UTF-16。
这样的话对于 length() 来说,由于它返回的是 Code Unit 的数量,那么对于在扩展平面的字符,Code Unit 是大于 1 的,所以就会出现返回的值比实际上输入的字符数大的情况。
而 codePointCount() 计算的是码点(Code Point)的数量,对于扩展平面来讲就可以覆盖到了。
但是这样的计算对于 Emoji 来说,仍旧是不完美的,看下面的例子:
| Emoji | String#length() | String#codePointCount() |
|---|---|---|
| ♀ | 1 | 1 |
| 🙂 | 2 | 1 |
| 👱♂ | 5 | 3 |
| 🏳️🌈 | 6 | 4 |
| 👩❤️💋👨 | 11 | 8 |
由于 Emoji 实际上可能由多个码点组成,所以靠 codePointCount() 也就没办法来计算了。
因此对于文章最开始提到的需求,使用 maxLength 是没办法很好限制的。
android:maxEms 属性
与 maxLength 类似,maxEms 最后也是由代码来承载的,但对于 EditText 来说 maxEms 和 ems 属性并不是说限制输入字符数量的,只是顺便一起写在文章里了。
在它的父类 TextView 里,这两个属性是用来限制自身的宽度的,从下面的代码里就可以看出。
public class TextView extends View implements ViewTreeObserver.OnPreDrawListener {
// ...
public TextView(
Context context, @Nullable AttributeSet attrs, int defStyleAttr, int defStyleRes) {
super(context, attrs, defStyleAttr, defStyleRes);
// ...
int maxlength = -1;
// ...
for (int i = 0; i < n; i++) {
int attr = a.getIndex(i);
switch (attr) {
// ...
case com.android.internal.R.styleable.TextView_maxEms:
setMaxEms(a.getInt(attr, -1));
break;
// ...
}
}
// ...
}
public void setMaxEms(int maxEms) {
mMaxWidth = maxEms;
mMaxWidthMode = EMS;
requestLayout();
invalidate();
}
}
首先我们要知道这里的 Ems 是什么,既然能这么写出来说明当然不是邮政的意思。一种相当古老的定义是,1 em 的宽度等于当前字体下的大写字母 M 的宽度。现代一点的定义是等于当前字号的宽度,比如说 16 点的字体下,1 em 的宽度就是 16 点。
对于 Android 中文环境下这个用起来还挺怪的,比较难以控制表现,不像 CSS 里 text-indext: 2em 就一定是开头空两格。这里就不展开讲了。
TextWatcher
对于监听用户输入,我们很容易就想到使用 TextWatcher。同样地限制用户输入也可以用这个:
class TextLengthWatcher(private val maxLength: Int = 30) : TextWatcher {
private var destCount: Int = 0
private var dStart: Int = 0
private var dEnd: Int = 0
override fun afterTextChanged(s: Editable) {
val count = s.length
if (count > maxLength) {
val lengthToDelete = count - maxLength // 要删除的长度
val deleteIndexStart = dEnd - lengthToDelete // 要删除的起始位置
if (deleteIndexStart < dEnd) {
s.delete(deleteIndexStart, dEnd)
}
}
}
override fun beforeTextChanged(s: CharSequence, start: Int, count: Int, after: Int) {
destCount = s.length
dStart = start // 输入的起始位置
dEnd = start + after // 输入的结束位置
}
override fun onTextChanged(s: CharSequence, start: Int, before: Int, count: Int) {
}
}
这里我们在用户输入的时候,会记录下本次输入的文本区间。在输入完成之后,如果输入长度大于 maxLength,会截断文本。
InputFilter
开头我们提到,android:maxLength 属性底层还是通过 InputFilter 来实现的。
public interface InputFilter
{
/**
* 当缓冲区将要用 source 的 start...end 区间替换 dest 的 dstart...dend 区间
* 时将会调用此方法。
* 返回替换之后的 CharSequence,可以是空字符串(在合适的情况下),或者返回 null
* 以便使用原来的替换。
* 注意不要拒绝长度为 0 的替换,这种情况发生在删除文本的时候。
* 同时注意,不应该对 dest 进行任何更改,只能根据上下文进行检查。
*
* 如果 source 是 Spanned 或 Spannable 的实例,那么 source 中的 span 对象应
* 该被复制到过滤之后的结果中(即非空返回值)。如果 span 的边界索引和 source 一致,
* 可以使用 TextUtils#copySpansFrom。
*/
public CharSequence filter(CharSequence source, int start, int end,
Spanned dest, int dstart, int dend);
}
注释看起来可能会一头雾水,先说说参数的意思:
source:在输入的时候就是输入的内容,在删除的时候是空序列start:输入内容的起始位置。一般为 0end:输入内容的结束位置,一般为输入内容的长度。在删除时为 0dest:在输入或删除前显示的内容dstart:待输入位置光标的起点。当输入时,如果光标位置在末尾,则值等于dest.length;如果光标位置在中间或开头,则值等于它实际在的位置。换句话来说这里是数间隔来确定光标位置,而不是数字符。dend:待输入位置光标的终点。当输入时一般等于dstart。特别地,如果是选中替换(删除也算一种选中替换),那么dstart是选中区间的光标的起始位置,dend则是对应的结束位置。某些会将击键字符串先上屏到文本框,等选词之后再将其替换为实际文本的输入法(如 Gboard),其输入等价于选中替换
返回值可以有以下几种类型:
null:不进行任何过滤操作,输入什么就是什么""空字符串:将source替换为空字符串,也就是不允许输入- 任意其他字符串:将
source替换为该字符串
举几个例子,比如说现在 EditText 里是“测试内容”四个字,那么当光标放在最后的时候,再输入字母 A,那么在回调这个方法的时候,传入的参数会是:
| <- 光标在这里 测 试 内 容 [A] <- 这里用 [A] 表示待上屏的字符 A 0 1 2 3 4 source = "A" start = 0 end = 1 dest = 测试内容 dstart = 4 dend = 4
如果我们将插入理解为“替换已有内容的最后的空字符串为新输入的内容”,那么很容易就明白为什么 dstart 和 dend 都是 4 了。因为 4 是原始内容里光标所在的位置。
当选中“试内”两个字,此时 dstart 为 1,dend 为 3。
当光标在末尾时,按下删除键,那么方法入参会是:
source = "" start = 0 end = 0 dest = "测试内容" dstart = 3 dend = 4
对于删除操作,我们可以将其理解为“替换最后一个字符为空字符串”,这样很容易就能理解为什么 source 是空字符串,start 和 end 都是 0。而既然是替换最后一个字符为空字符串,那就要先选中最后一个字符,所以 dstart 会是光标的倒数第 2 个位置,dend 会是光标的最后一个位置。
知道了 InputFilter 的原理之后,我们再来看看前面提到的官方的实现类 InputFilter.LengthFilter:
/**
* This filter will constrain edits not to make the length of the text
* greater than the specified length.
*/
public static class LengthFilter implements InputFilter {
@UnsupportedAppUsage
private final int mMax;
public LengthFilter(int max) {
mMax = max;
}
public CharSequence filter(CharSequence source, int start, int end, Spanned dest,
int dstart, int dend) {
// (dend - dstart) 是待变更区间的长度。对于输入的时候来说是 0,对于删除的时候来说是删除内容的长度
// (dest.length() - (dend - dstart)) 是原始内容去掉待变更区间之后还剩的长度。对于输入的时候来说结果等于当前内容长度,对于删除的时候来说结果等于删除之后的内容长度
// 所以 keep 最终的结果就是在变更结束之后还能再允许变更多长
int keep = mMax - (dest.length() - (dend - dstart));
if (keep <= 0) { // 小于等于 0 了,说明即使不输入也已经达到上限了,所以不允许输入了
return "";
} else if (keep >= end - start) { // 剩的比要输入的内容多,允许输入
return null; // keep original
} else { // else 分支处理 0 < keep < 输入内容长度的情况,也就是剩下的长度不足以容纳全部输入内容,要开始截断了
keep += start; // 加上 start 之后就是要从 source 里截取的长度了
if (Character.isHighSurrogate(source.charAt(keep - 1))) { // 如果最后一个字符是 UTF-16 前导代理,那么指针需要前移,避免意外截断
--keep;
if (keep == start) { // 移动之后如果到了开头,说明不能在保证输入内容满足 UTF-16 合法性的情况下截断,因此放弃,直接禁止输入
return "";
}
}
return source.subSequence(start, keep); // subSequence 的参数是左闭右开区间,keep - 1 位置一定是一个后尾代理,可以构成合法的 UTF-16 码位
}
}
/**
* 返回此输入过滤器所能允许的最大长度
*/
public int getMax() {
return mMax;
}
}
详细的内容已经在注释里标出了。这里涉及到的一点 UTF-16 知识在开头已经讲过,不再赘述。
InputConnection
InputConnection 是沟通输入法和应用内接受文本输入的 View(在这里就是 EditText)的桥梁。输入法触发的 Key Event 和文字的添加、删除,都会先传给与 EditText 绑定的 InputConnection 处理,然后再上屏。它是一个接口,一般常用的有这么 4 个方法:
public interface InputConnection {
// ...
// 当输入法提交字符上屏的时候会回调该方法
boolean commitText(CharSequence text, int newCursorPosition);
// 当有按键输入时,会回调该方法。
// 但不同输入法对于 Key Event 的处理不一样,搜狗输入法在删除的时候会回调该方法,
// 而 Gboard 输入法会回调下面的 deleteSurroundingText() 方法
boolean sendKeyEvent(KeyEvent event);
// 当有文本删除操作时(剪切、退格等),会回调该方法
boolean deleteSurroundingText(int beforeLength, int afterLength);
// 结束组合文本的时候,回调该方法
boolean finishComposingText();
// ...
}
需要注意的是,EditText 并没有对外暴露能够直接设置 InputConnection 的方法,因此我们需要继承 EditText 然后手动重写 onCreateInputConnection() 方法。
另外,InputConnection 里需要重写的方法实在是太多了,而对于限制输入长度,我们只需要用到 commitText(),所以方便起见这里我们继承 InputConnectionWrapper。整体上的思路和 InputFilter 差不多:
class CustomEditText @JvmOverloads constructor(context: Context, attrs: AttributeSet? = null, defStyleAttr: Int = 0): EditText(context, attrs, defStyleAttr) {
override fun onCreateInputConnection(outAttrs: EditorInfo): InputConnection? {
return CustomInputConnection(super.onCreateInputConnection(outAttrs))
}
inner class CustomInputConnection(
target: InputConnection?,
private val maxLength: Int = 30,
): InputConnectionWrapper(target, false) {
override fun commitText(source: CharSequence, newCursorPosition: Int): Boolean {
val count = source.length // 输入内容的长度
val destCount = if (selectionStart == selectionEnd) {
text.length
} else {
text.subSequence(selectionStart, selectionEnd).length
}
if (count + destCount > maxLength) {
val lengthToDelete = count + destCount - maxLength
val deleteIndexStart = count - lengthToDelete
return super.commitText(
if (deleteIndexStart > 0) source.subSequence(0, deleteIndexStart) else "", // 能截断就截断,不够截断了就禁止输入
newCursorPosition
)
}
return super.commitText(source, newCursorPosition)
}
}
}
但实测下来,InputConnection 有挺多坑的。除了上面注释提到的之外,还有这么几个问题:
- 外接实体键盘的输入不会触发
commitText() - 像 Gboard 输入法,会首先将击键字符串上屏,等选词之后再将其替换为实际输入的内容。这部分击键字符串会被计算在 EditText 的内容长度里进而影响到我们在
commitText()里计算剩余长度。也就是说,当限制最多输入 30 个字而已经输入了 28 个字的时候,再输入一个“好”,由于它的拼音是 hao,比剩下的 2 个字要多,所以这个字最终无法上屏
正确计算文本长度
上面讲了几种限制输入长度的办法,以及为什么使用 String#length 和 String#codePointCount 都无法正常满足我们要同时考虑中文、非中文和 Emoji 字符的需求。在举例过程中为了方便起见我还是用的 length 属性。这一节我们来看看如果想要做到最开始的需求,需要怎么办。
首先再来回顾一下需求内容:
总上限 30 个字,汉字和 Emoji 算一个字,英文和数字算 0.5 个字。
众所周知写代码能用整数就不用浮点数,我们稍微调整一下:
总上限 60 个字,全角字符和 Emoji 算 2 个字,半角字符算 1 个字。
但是这里又引入了一个新的问题,怎么判断全角和半角。
在 Unicode 中,对码位使用 East_Asian_Width 标记其宽度类型,它可以有以下值:
- A,Ambiguous,根据上下文决定
- F,Fullwidth,全角
- H,Halfwidth,半角
- N,Neutral,中立,作为半角
- Na,Narrow,半角
- W,Wide,全角
在 Unicode 官方发布的 EastAsianWidth.txt 文件中列举了所有已经显式标记的码位。而对于不在该文件中的字符,若满足以下条件,则标记为 W 全角:
- the CJK Unified Ideographs Extension A block,对应区间:U+3400 ~ U+4DBF
- the CJK Unified Ideographs block,对应区间:U+4E00 ~ U+9FFF
- the CJK Compatibility Ideographs block,对应区间:U+F900 ~ U+FAFF
- the Supplementary Ideographic Plane,对应区间: U+20000 ~ U+2FFFF
- the Tertiary Ideographic Plane,对应区间:U+30000 ~ U+3FFFF
其余的均为 N。
这下需求好像变得更复杂了?那我们最后再简化一下:
总上限 60 个字,汉字和 Emoji 算 2 个字,其他字符算 1 个字。
这样这个需求在转述为这句描述之后,我们就可以写代码了——才怪。
汉字好办,我们可以用网上流传甚广的一个不那么准确的正则表达式来处理:[u4e00-u9fff],于是可以写出这样的扩展函数:
fun Character.isCJK() = toString().matches("[u4e00-u9fa5]".toRegex())
这个正则表达式的区间是中日韩统一表意文字的范围,实际上还会有一些字在这个范围之外,不过对于一般的业务场景来说足够了。
那么 Emoji 呢?这可是个麻烦事了。Emoji 可以由好多个码点组成,Unicode 官方给出的 EBNF 定义是:
possible_emoji :=
flag_sequence
| zwj_element (\x{200D} zwj_element)+
flag_sequence :=
\p{RI} \p{RI}
zwj_element :=
\p{Emoji} emoji_modification?
emoji_modification :=
\p{EMod}
| \x{FE0F} \x{20E3}?
| tag_modifier
tag_modifier :=
[\x{E0020}-\x{E007E}]+ \x{E007F}
看到这个定义,相信第一反应一定是,写个状态机来处理。在开始写这篇文章的时候偶然找到了一个开源的实现 EmojiReader 帮我们完成了这个事情。
所以最后我们要做的事情,就是成为调包侠!
val EmojiReader.Node.characterCount: Int
get() = if (isEmoji) { // 优先处理 Emoji
2
} else {
if (codePoint.size == 1) {
val codePoint = codePoint.first()
if (codePoint in (0x4e00)..(0x9fa5)) { // 在这个区间里认为是汉字
2
} else {
1
}
} else {
1
}
}
val CharSequence.characterCount: Int
get() = EmojiReader.analyzeText(this).sumOf { it.characterCount }
几种不同的统计方式结果如图:
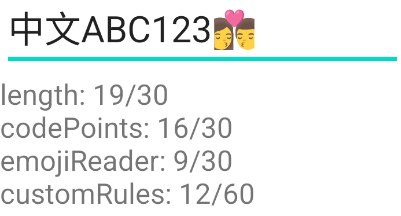
customRules 就是按照需求描述计算出来的长度。
现在长度计算有了,那么最后一步就是开始限制最大输入长度。到这里我们很容易就明白,能够在尽可能减少副作用的情况下满足需求的选择就是 TextWatcher 和 InputFilter 了,这里以 InputFilter 为例。
之前说了官方的 LengthFilter 是基于 length 实现的,并且 filter() 入参里的数字也全是以 length 为基准,因此这部分数据就不能直接使用了。好在入参里有 source 和 dest,我们可以手动来计算另外几个参数。
还是一步一步来,这里先给出“总上限 30 个字,所有字符都算 1 个字”的限制实现:
class CustomLengthFilter(val max: Int): InputFilter {
override fun filter(source: CharSequence, start: Int, end: Int, dest: Spanned, dstart: Int, dend: Int): CharSequence? {
val destCodePoints = EmojiReader.analyzeText(dest)
val destNormalCharacterCount = destCodePoints.size
val sourceCodePoints = EmojiReader.analyzeText(source)
val sourceNormalCharacterCount = sourceCodePoints.size
// 原来的 dend - dstart 这里就需要手动计算了
var diff = dend - dstart
var realDiff = 0
while (diff > 0) { // diff 的值实际上就是每个码点的长度
diff -= destCodePoints[realDiff++].length // 所以这里我们要找到实际的码点
}
var keep = max - (destNormalCharacterCount - realDiff)
if (keep <= 0) {
return ""
} else if (keep >= sourceNormalCharacterCount) {
return null
} else {
keep += start // 由于 start 似乎一般都为 0,所以这里不加应该也没关系
// 因为我们直接用 EmojiReader 的实现,所以这里就不再需要像官方实现一样判断前导代理了,可以直接截断
return EmojiReader.subSequence(source, start, keep)
}
}
}
效果如图:
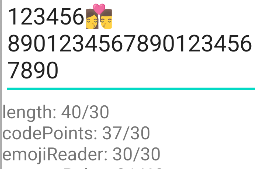
要真正实现我们需求的会更麻烦一点,我们需要自己来定义每一个码点的长度计算规则。对于 EmojiReader 来说,一个码点就是一个 EmojiReader.Node 对象,所以这里可以直接用上面写的扩展属性 characterCount。最后组装出来的 InputFilter 就是:
class CustomLengthFilter(val max: Int) : InputFilter {
override fun filter(source: CharSequence, start: Int, end: Int, dest: Spanned, dstart: Int, dend: Int): CharSequence? {
val destCodePoints = EmojiReader.analyzeText(dest)
val destNormalCharacterCount = dest.characterCount
val sourceCodePoints = EmojiReader.analyzeText(source)
val sourceNormalCharacterCount = source.characterCount
var diff = dend - dstart
var realDiff = 0
while (diff > 0) {
diff -= destCodePoints[realDiff++].characterCount
}
var keep = max - (destNormalCharacterCount - realDiff)
if (keep <= 0) {
return ""
} else if (keep >= sourceNormalCharacterCount) {
return null
} else {
keep += start // 这里的 keep 是按照我们规则想要的 keep,但并不能直接用来截断字符串
var actualKeep = 0 // 我们需要按照 1 对 1 的规则来重新计算一个 keep 用于截断字符串
while (keep > 0) {
val currentCharacterCount = sourceCodePoints[actualKeep].characterCount
if (currentCharacterCount > keep) {
break
}
keep -= currentCharacterCount
actualKeep++
}
return EmojiReader.subSequence(source, start, actualKeep)
}
}
}
效果如图:

不足
到这里其实我们的需求就基本上满足了。但实测下来,无论是我们自己实现的 InputFilter,还是官方给的 LengthFilter,对于 Gboard 这种会提前把击键字符串上屏的输入法来说,都会存在前文提到的问题。考虑到绝大多数情况下业务是面向国内用户的,而目前主流的国产输入法都不会先上屏击键字符串,所以这部分问题暂且可以忽略。
参考资料
EditText 限制输入字符个数的三种方式 - 掘金 (juejin.cn)