自己选的课,哭着也要上完。
本学期开始进行专业方向分流,我分到的方向是网络与通信软件方向。最开始以为选修课学分还差一点,所以选择了这门课 Web 开发方向的专业课。不过最后发现其实学分已经够了。算了,选都选了又没法退,就硬着头皮上吧。不过话说回来将这门课作为 Web 方向的第一门专业课总有种奇怪的感觉……
言归正传,这门课主要学习的是非关系型数据库,以 Hadoop、Redis 和 Memcached 为主要实例。而四次上机实验的内容则是关于 Hadoop 和 Redis 的配置以及使用。在这里记录一下踩坑的全过程。
本文具体的实验环境如下:宿主机系统 Windows 10 专业版(2004),虚拟机软件 VMware Workstation 16,虚拟机系统 Ubuntu 20.04.1(x64)。注意这里使用的虚拟机系统并非是推荐的 CentOS。
在继续阅读之前,请确保已经完成环境的配置(系统的安装、VMware Tools 的安装等),同时也建议执行一次 sudo apt update && sudo apt upgrade。
实验一:Hadoop 和 HBase 的安装和配置
第一次实验的目标是配置 Hadoop(含 HDFS、MapReduce 和 YARN)和 HBase。使用的软件和具体版本号为:Hadoop 3.1.4、HBase 2.2.6。这里我们仅配置一主一从伪分布式环境。
需要注意的是,HBase 对 Hadoop 的版本有着严格的要求,具体可以查看 Hadoop version support matrix。经过测试 Hadoop 3.3.0 无法和现有的 HBase 版本配合使用。
前期准备
为了便于后续操作,我们专门添加一个用于 Hadoop 的用户,用户名和密码均为 hadoop。输入以下命令:
sudo useradd -m hadoop -s /bin/bash sudo passwd hadoop sudo adduser hadoop sudo su - hadoop sudo apt update
接下来进行一些环境准备操作,此时请保持在 hadoop 用户下。使用 sudo apt install openjdk-8-jdk 安装好 OpenJDK(目前 Apache 官方推荐使用 OpenJDK 而不是 Oracle JDK)。不过这样安装的 OpenJDK 默认不会配置好环境变量,所以需要手动配置,将下列配置加入到 ~/.bashrc 文件中:
# Java Environment
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存之后,使用 source ~/.bashrc 使修改生效。继续输入 java -version,如果正确显示 JDK 版本,即说明配置完成。
然后继续使用下列命令安装 SSH:
sudo apt-get install openssh-server ssh localhost exit cd ~/.ssh/ ssh-keygen -t rsa
执行 ssh-keygen 命令之后,连续三次回车。第一次是将 Key 存放于默认位置,第二次和第三次是 passphrase 相关的操作。完成之后继续执行:
touch authorized_keys chmod 600 authorized_keys cat ./id_rsa.pub >> ./authorized_keys ssh localhost
这时会发现登录本机的 SSH 已经不再需要密码了。
Hadoop 的配置
切到保存有下载好的 hadoop-3.1.4.tar.gz 文件的文件夹,执行下列命令进行安装。这里为了方便,我们将解压出来的文件夹改名为 hadoop。
sudo tar -zxvf hadoop-3.1.4.tar.gz -C /usr/local cd /usr/local sudo mv hadoop-3.1.4 hadoop sudo chown -R hadoop ./hadoop
然后加入 Hadoop 的环境变量,方法与之前配置 JDK 环境变量相同:
# Hadoop Environment export HADOOP_HOME=/usr/local/hadoop export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
完成之后输入 hadoop version,如果出现 Hadoop 版本即说明成功。下面开始配置伪分布式环境。
切到 /usr/local/hadoop/etc/hadoop 文件夹,修改 hadoop-env.sh 文件,主要是指定 JAVA_HOME,在文件开头部分找到被注释掉的 export JAVA_HOME=,将其取消注释,并将等号后面的路径修改为之前的 JAVA_HOME 环境变量的值,在本文的示例中即为 /usr/lib/jvm/java-8-openjdk-amd64。
然后修改 core-site.xml 文件:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改 hdfs-site.xml 文件,在 <configuration> 节加入:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
修改 yarn-site.xml 文件:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
修改 mapred-site.xml 文件:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
保存上述文件,然后开始准备格式化 NameNode。按照本文流程来说,到这里应该是第一次格式化,所以没有什么太大的问题。如果是在已有数据的情况下想要重新格式化,则需要删除所有的数据 data 和日志 log。否则会导致 NameNode 和 DataNode 的集群 ID 不一致。
cd /usr/local/hadoop/bin hdfs namenode -format
完成之后,启动 Hadoop 检查我们的配置结果:
cd /usr/local/hadoop/sbin ./start-dfs.sh ./start-yarn.sh jps
在输出中出现 Jps、NameNode、DateNode、SecondaryNameNode 和 ResourceManager 即为成功。此时打开浏览器,访问 localhost:50070 可以查看到下列页面:
访问 localhost:8088 可以查看到下列页面,这是 YARN 提供的:
点击左侧的 Nodes,可以查看到我们配置的节点信息:
接下来,我们运行一次经典的 WordCount 来测试 Hadoop。
hdfs dfs -mkdir /input # 创建 input 文件夹 hdfs dfs -put /usr/local/hadoop/LICENSE.txt /input/test.txt # 上传一个测试文件 hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /input/test.txt /output/
此时会有类似于下列内容的输出:
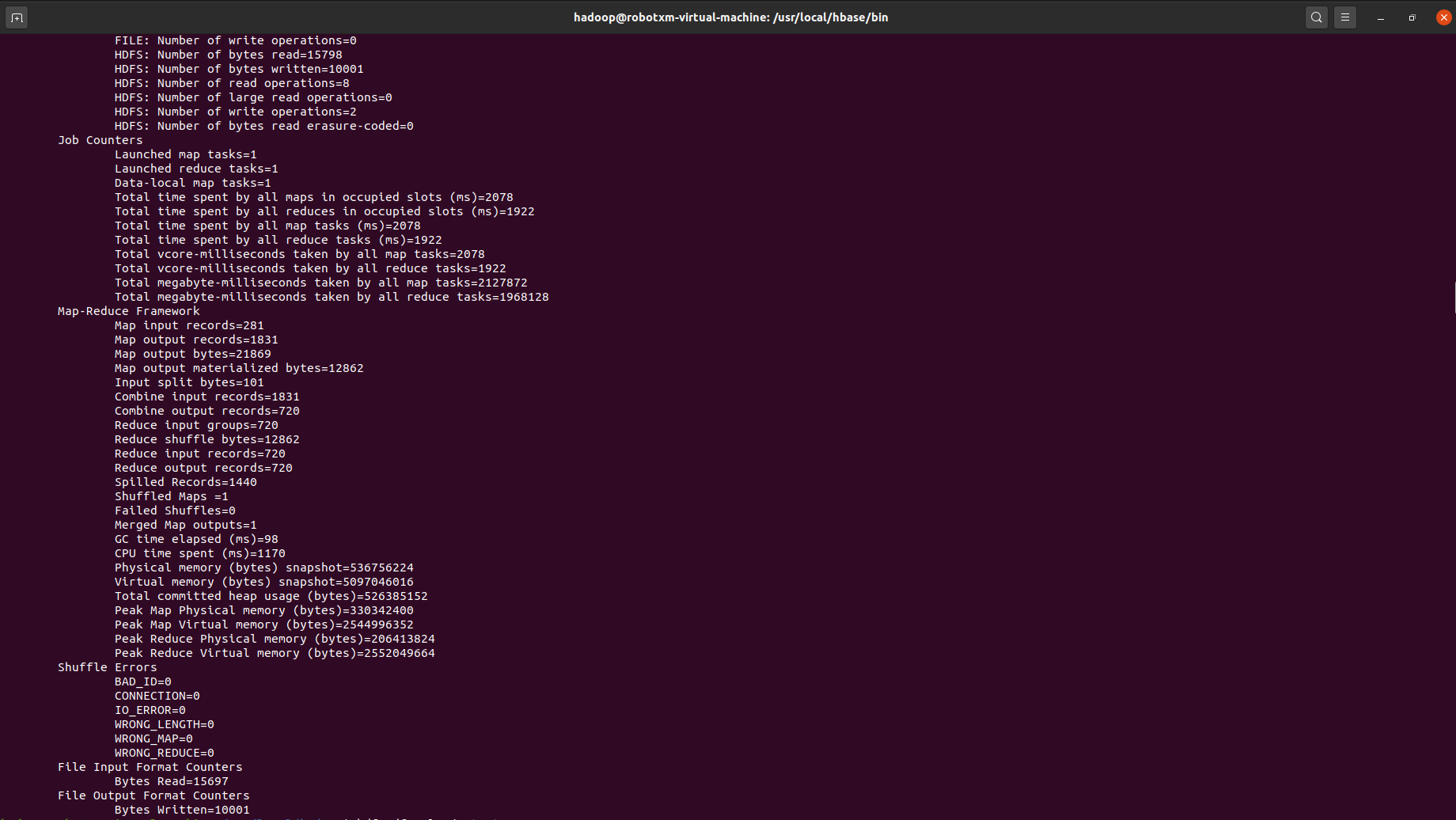
完成之后执行 hdfs dfs -ls /output,可以看到有如下两个文件生成:

我们运行 hdfs dfs -cat /output/part-r-00000 查看一下 part-r-00000 文件的内容,即为 WordCount 的输出结果:
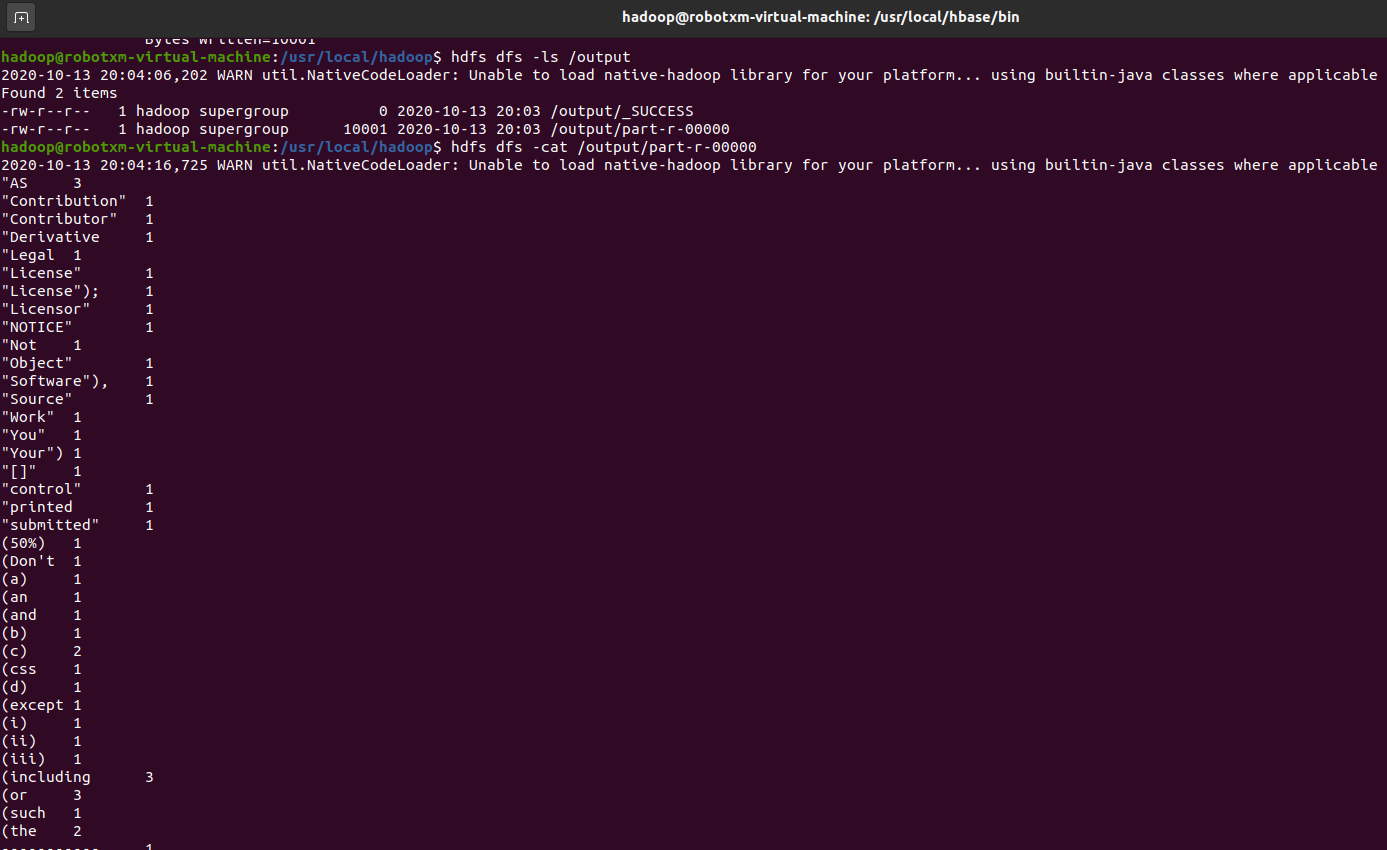
符合预期。当然我们还可以通过之前的网页控制台查看 HDFS 中的文件。
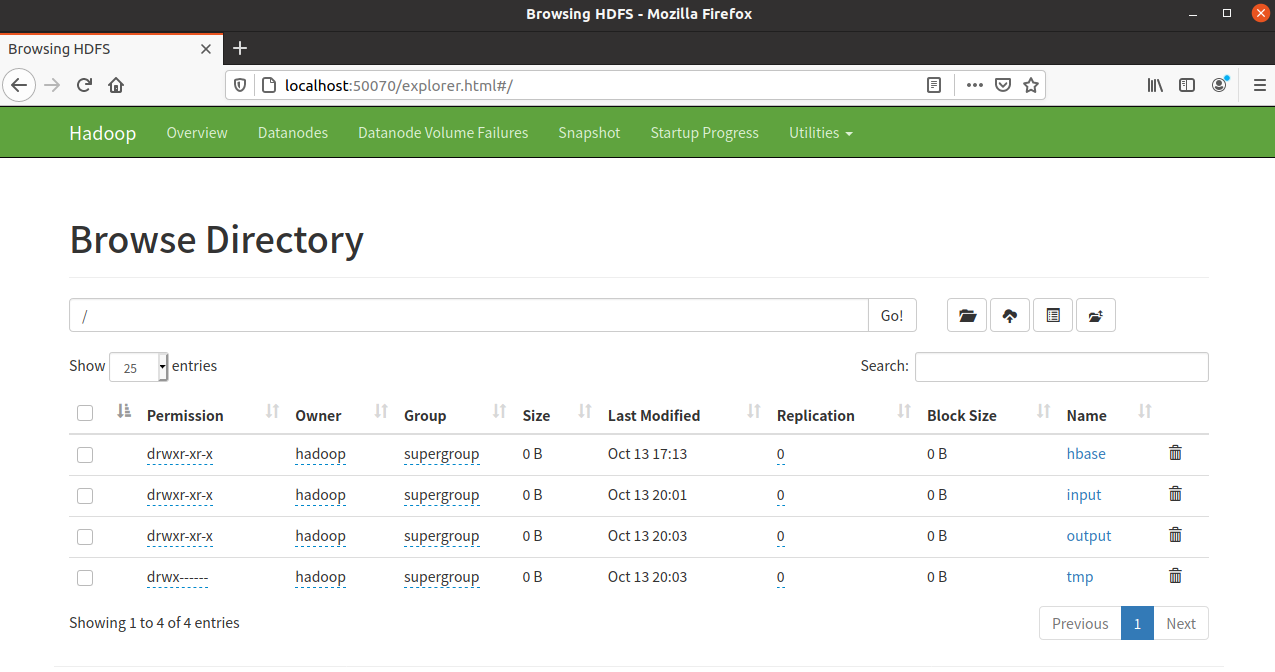
至此 Hadoop 配置完成。
HBase 的配置
继续保持在 hadoop 用户下。切到有下载好的 hbase-2.2.6-bin.tar.gz 文件的文件夹中,执行:
sudo tar -zxvf hbase-2.2.6-bin.tar.gz -C /usr/local cd /usr/local sudo mv hbase-2.2.6-bin hbase sudo chown -R hadoop ./hbase
配置环境变量:
# HBase Environment HBASE_HOME=/usr/local/hbase
和之前 Hadoop 一样,切到 $HBASE_HOME/conf 文件夹,修改 hbase-env.sh,设置环境变量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
继续修改 hbase-site.xml:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
确保已经按照前文所述启动了 Hadoop。切到 /usr/local/hbase/bin 文件夹,执行 ./start-hbase.sh 启动 HBase。然后执行 jps 查看运行情况。
如果出现 HMaster、HRegionServer 和 HQuorumPeer,即为成功运行,如下图所示:
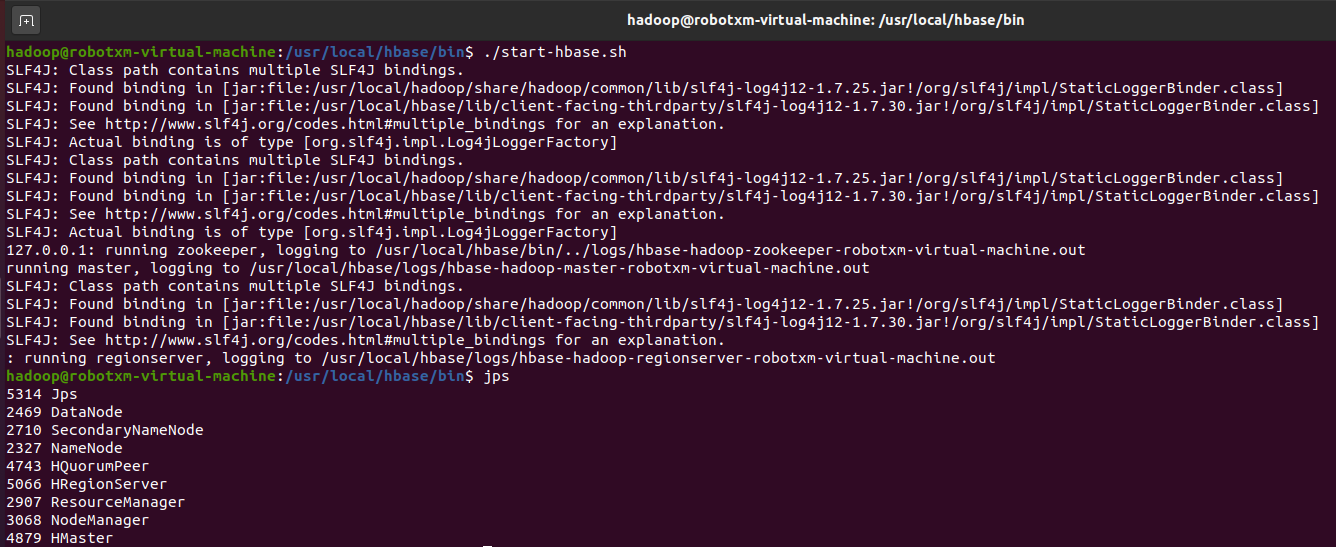
访问 localhost:16010,可以看到如下页面:
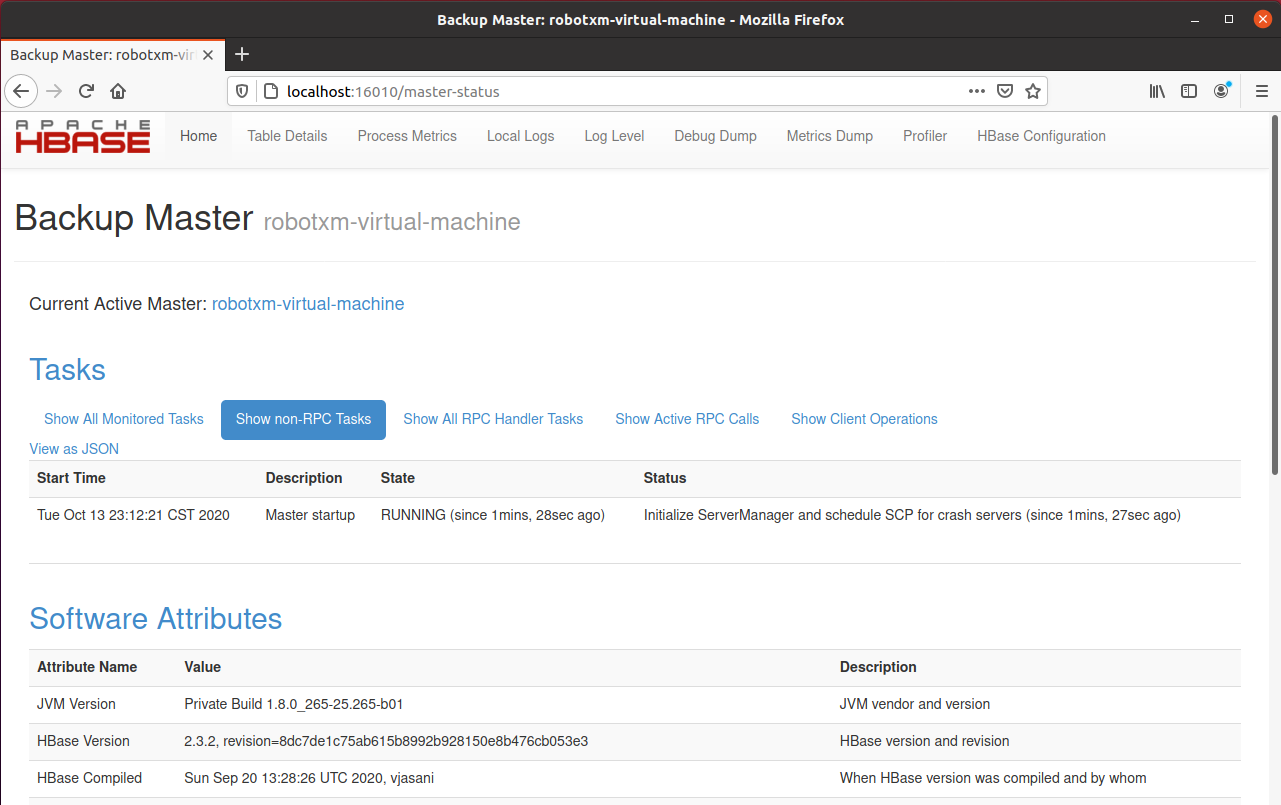
至此,HBase 配置完成。
实验二:HBase 的使用
之前实验一的内容写的有点多了,其实 HBase 的配置应该是实验二里的内容,不过问题不大。
首先确保 Hadoop 和 HBase 正在运行,运行方法参照实验一中提到的命令。然后使用以下命令进入 HBase 的 Shell 环境:
cd /usr/local/hbase/bin ./hbase shell
Shell 环境如下所示(可以忽略“无效的变量名”报错):
输入命令 list 可以查看所有的表。当然目前我们的数据库是空的,所以什么都没有:

下面开始建表过程。这里对于 HBase 的行键、列族等概念不再阐述。考虑如下数据表:
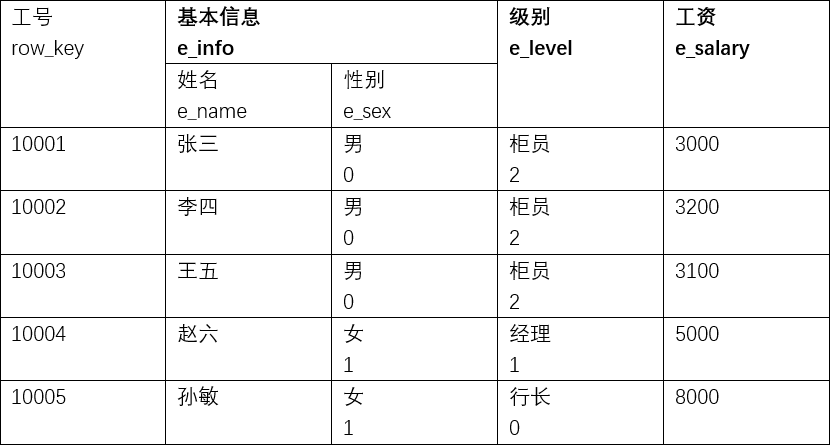
其中加粗的表头为列族,其下属为列。这里我们用工号作为行键。
然后开始创建数据表。命令格式为 create '<table_name>,'<column_family_1>','<column_family_2>'...。
create 'bank','e_info', 'e_level', 'e_salary'

完成之后我们向表中插入数据。由于 HBase 的特性,我们需要逐个单元格进行添加。命令格式为 put '<table_name>','<row_key>','<column_family>:<column>','value'。
put 'bank','10001','e_info:e_name','张三' put 'bank','10001','e_info:e_sex','0' put 'bank','10001','e_level','2' put 'bank','10001','e_salary','3000' put 'bank','10002','e_info:e_name','李四' put 'bank','10002','e_info:e_sex','0' put 'bank','10002','e_level','2' put 'bank','10002','e_salary','3200' put 'bank','10003','e_info:e_name','王五' put 'bank','10003','e_info:e_sex','0' put 'bank','10003','e_level','2' put 'bank','10003','e_salary','3100' put 'bank','10004','e_info:e_name','赵六' put 'bank','10004','e_info:e_sex','1' put 'bank','10004','e_level','1' put 'bank','10004','e_salary','5000' put 'bank','10005','e_info:e_name','孙敏' put 'bank','10005','e_info:e_sex','1' put 'bank','10005','e_level','0' put 'bank','10005','e_salary','8000'
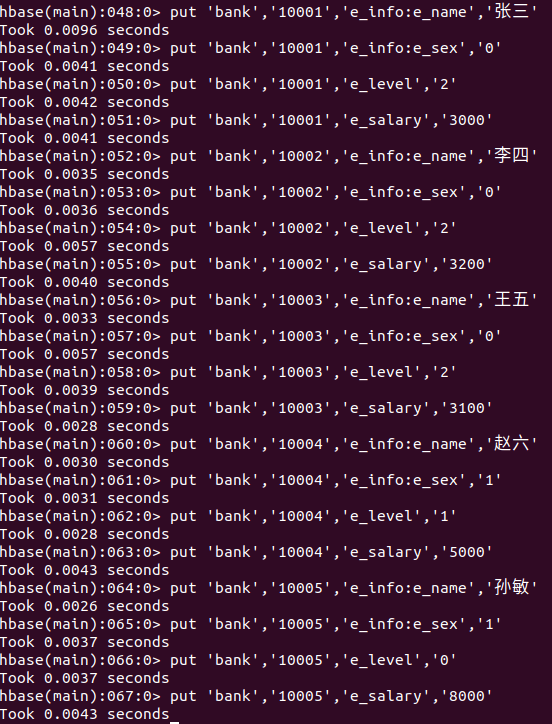
插入完成之后,就可以开始查询数据了。命令格式为 `get '<table_name>','<row_key>'{,<codition>}`,其中 <condition> 部分是可选的。比如在不设置条件的时候,我们查询的就是行键所代表的一整行数据:
get 'bank','10001'
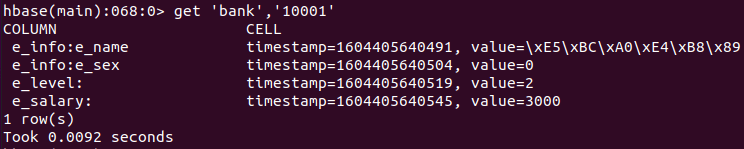
当然也可以指定列族或者列进行查询,加上条件即可:
# 指定列族
get 'bank','10001',{COLUMN => 'e_info'}
# 指定列族和列
get 'bank','10001',{COLUMN => 'e_info:e_name'}

我们也可以一次性查询整张表的数据,命令格式为 scan '<table_name>'。
scan 'bank'
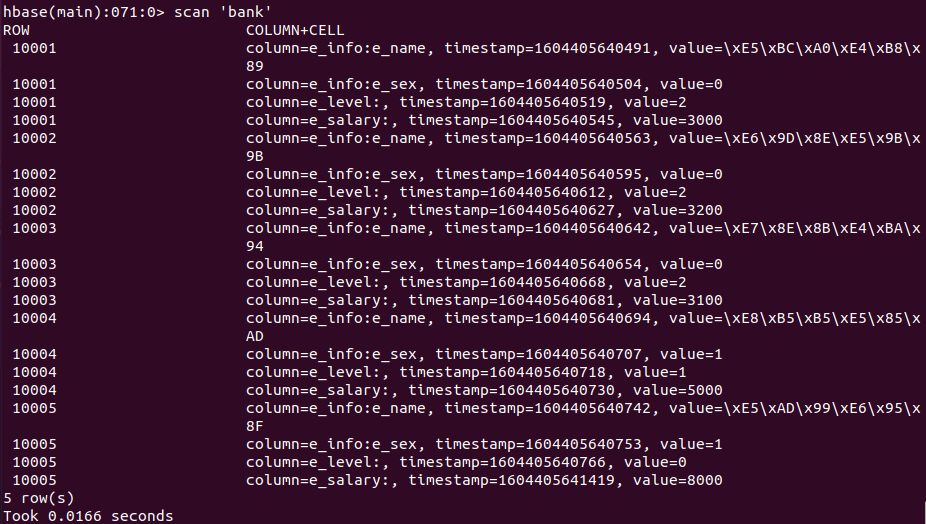
如果需要更新数据,直接插入新的数据即可:
put 'bank','10001','e_salary','3300'

使用 delete '<table_name>','<row_key>','<column_family:column>' 删除某一行中,某一列族下的某一列的数据:
# 假定我们已经添加了下列数据 put 'bank','10006','e_info:e_name','测试' put 'bank','10006','e_info:e_sex','0' put 'bank','10006','e_level','2' put 'bank','10006','e_salary','2000' # 执行删除 delete 'bank','10001','e_info:e_sex'

当然也可以直接删除一行。命令格式为 deleteall '<table_name>','<row_key>'
deleteall 'bank','10001'
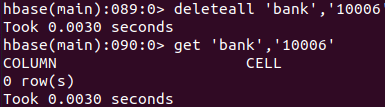
以上就是 HBase 的基本使用。
实验三:Redis 的安装和配置
因为 Ubuntu 的软件源里包含了 Redis 服务器,所以安装和配置还是比较简单的。安装的话直接一句 sudo apt install redis-server 就好。装好之后可以使用 ps -aux|grep redis 看到 Redis 已经开始运行了,如下图所示。

配置文件方面的话,没有太多要修改的地方。通过 Ubuntu 软件源安装的 Redis 默认已经启用了守护进程,我们需要修改的就是增加一下登录密码以提高安全性。打开 /etc/redis/redis.conf 文件,搜索 requirepass 字段,取消注释,并在后面设置密码,比如:
requirepass redis
保存之后,执行 sudo service redis-server restart 重启 Redis 服务器。然后我们可以借助先前安装 Redis 时自动装好的命令行工具 redis-cli 访问 Redis。
由于我们设置了密码,所以在运行命令行工具的时候需要传递密码参数,执行 redis-cli -a redis。进入命令行工具之后,输入 ping 可以查看连接情况,如果连接正常,会得到 PONG 的响应。如果没有提供密码,或是提供了错误的密码,将不会得到正确的响应。
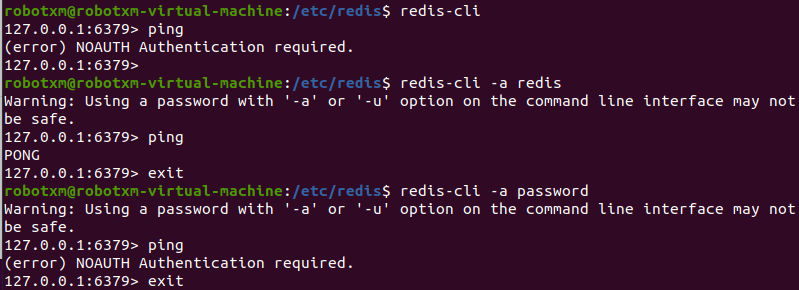
这样 Redis 就算配置完成了。
实验四:Redis 的使用
考虑如下教师和学生信息表:
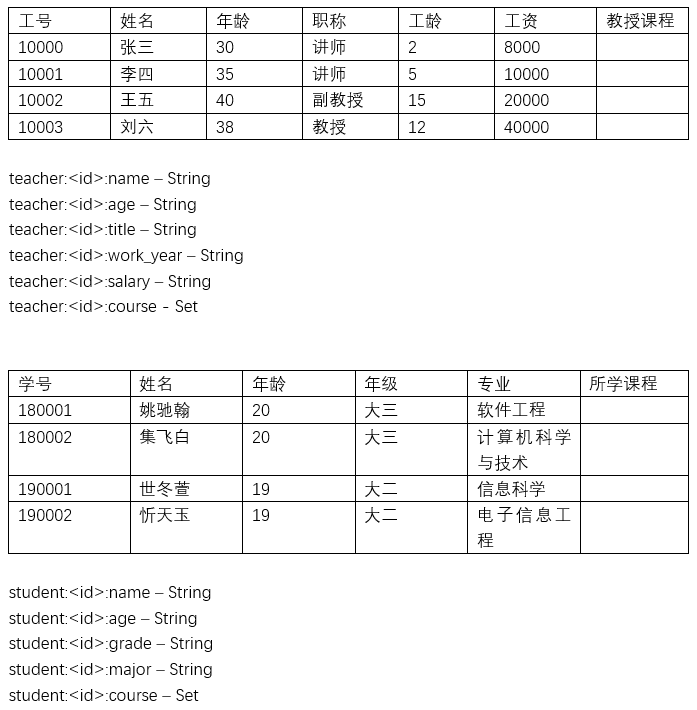
在上图中,已经列出了使用 Redis 组织数据的形式。使用下列命令插入数据:
set 'teacher:10000:name' '张三' set 'teacher:10000:age' '30' set 'teacher:10000:title' '讲师' set 'teacher:10000:work_year' '2' set 'teacher:10000:salary' '8000' sadd 'teacher:10000:course' '编译原理' '面向对象程序设计' '计算机导论与程序设计' set 'teacher:10001:name' '李四' set 'teacher:10001:age' '35' set 'teacher:10001:title' '讲师' set 'teacher:10001:work_year' '5' set 'teacher:10001:salary' '10000' sadd 'teacher:10001:course' '计算机组成与设计' '操作系统' set 'teacher:10002:name' '王五' set 'teacher:10002:age' '40' set 'teacher:10002:title' '副教授' set 'teacher:10002:work_year' '15' set 'teacher:10002:salary' '20000' sadd 'teacher:10002:course' '数据库概论' '离散数学' set 'teacher:10003:name' '刘六' set 'teacher:10003:age' '38' set 'teacher:10003:title' '教授' set 'teacher:10003:work_year' '12' set 'teacher:10003:salary' '40000' sadd 'teacher:10003:course' '计算机网络' '通信技术基础' set 'student:180001:name' '姚驰翰' set 'student:180001:age' '20' set 'student:180001:grade' '大三' set 'student:180001:major' '软件工程' sadd 'student:180001:course' '数据库概论' '计算机组成与设计' set 'student:180002:name' '集飞白' set 'student:180002:age' '20' set 'student:180002:grade' '大三' set 'student:180002:major' '计算机科学与技术' sadd 'student:180002:course' '数据库概论' '计算机网络' set 'student:190001:name' '世冬萱' set 'student:190001:age' '19' set 'student:190001:grade' '大二' set 'student:190001:major' '信息科学' sadd 'student:190001:course' '计算机导论与程序设计' set 'student:190002:name' '忻天玉' set 'student:190002:age' '19' set 'student:190002:grade' '大二' set 'student:190002:major' '电子信息工程' sadd 'student:190002:course' '计算机导论与程序设计'
插入完成之后,使用 keys * 命令可以查看到所有的 Key。
使用 get 'teacher:10001:name' 可以获取到这个指定 Key 对应的值。中文在存储时会被编码。

对于 Set 类型的数据,可以使用 sadd <key> <value1> <value2> ... 命令追加数据,比如 sadd 'teacher:10001:course' '数据结构'。

使用 srem <key> <value1> <value2> ... 可以 Set 中的值。比如 srem 'teacher:10001:course' '数据结构'。

还可以求两个 Set 的差集,命令是 sdiff <set_name1> <set_name2>。比如 sdiff 'student:180001:course' 'student:180002:course'。

差不多这些就是前面插入数据时涉及到的 Redis 数据结构的一些常用操作了。